this post was submitted on 28 Jan 2025
1092 points (97.6% liked)
Microblog Memes
6325 readers
3162 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
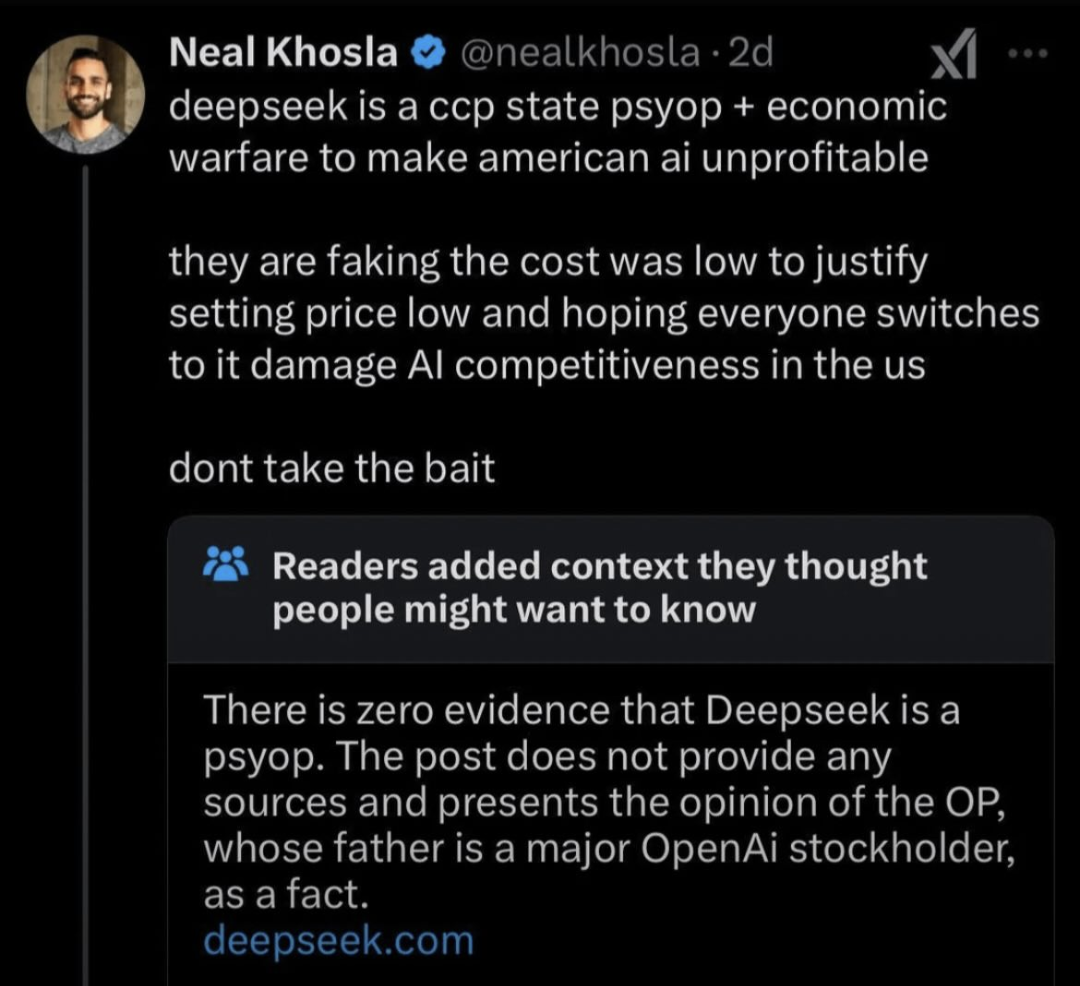
So here's my take on the whole stolen training data thing. If that is true, then open AI should have literally zero issues building a new model off of the full output of the old model. Just like deepseek did. But even better because they run it in house. If this is such a crisis, then they should do it themselves just like China did. In theory, and I don't personally think this makes a ton of sense, if training an LLM on the output of another LLM results in a more power efficient and lower hardware requirement, and overall better LLM, then why aren't they doing that with their own LLMs to begin with?.