this post was submitted on 28 Jan 2025
1097 points (97.6% liked)
Microblog Memes
6333 readers
3093 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
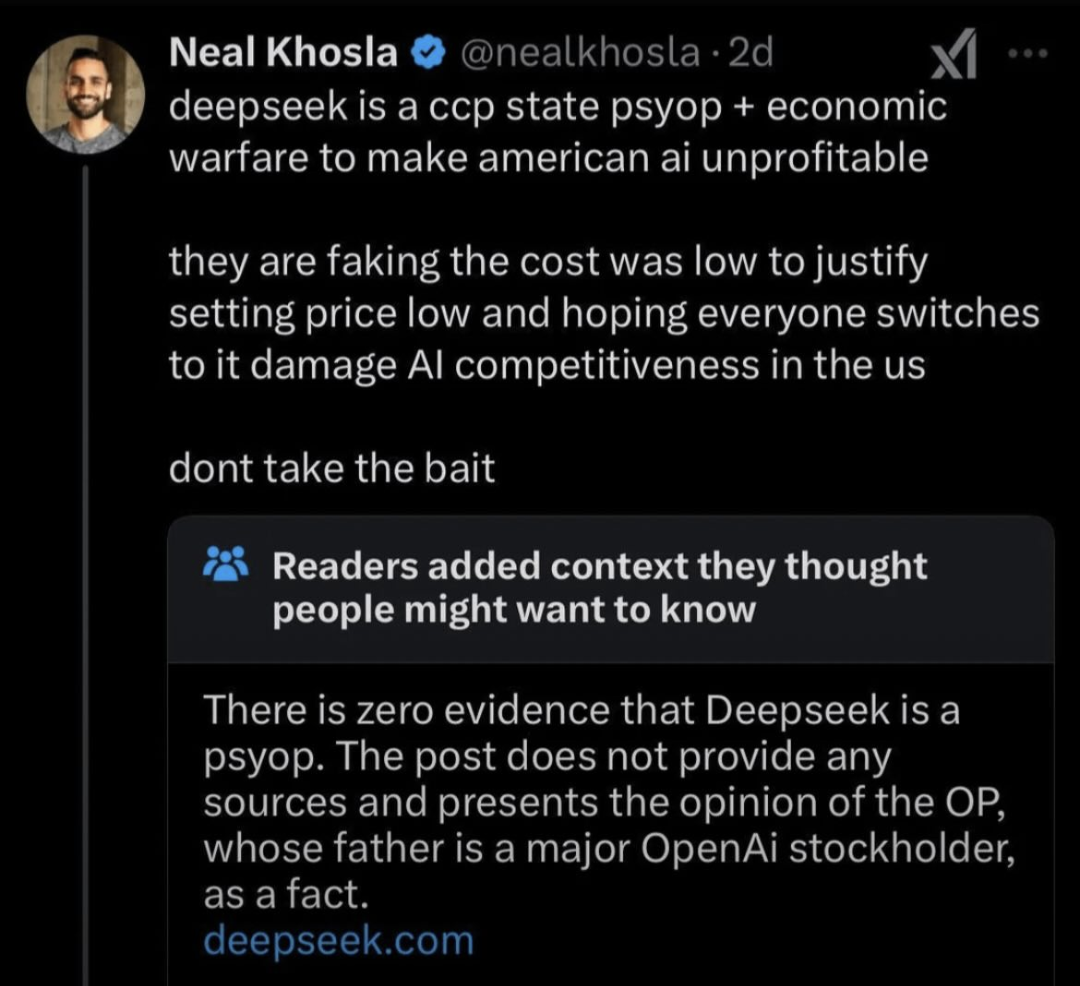
If you take into account the optimizations described in the paper, then the cost they announce is in line with the rest of the world's research into sparse models.
Of course, the training cost is not the whole picture, which the DS paper readily acknowledges. Before arriving at 1 successful model you have to train and throw away n unsuccessful attempts. Of course that's also true of any other LLM provider, the training cost is used to compare technical trade-offs that alter training efficiency, not business models.