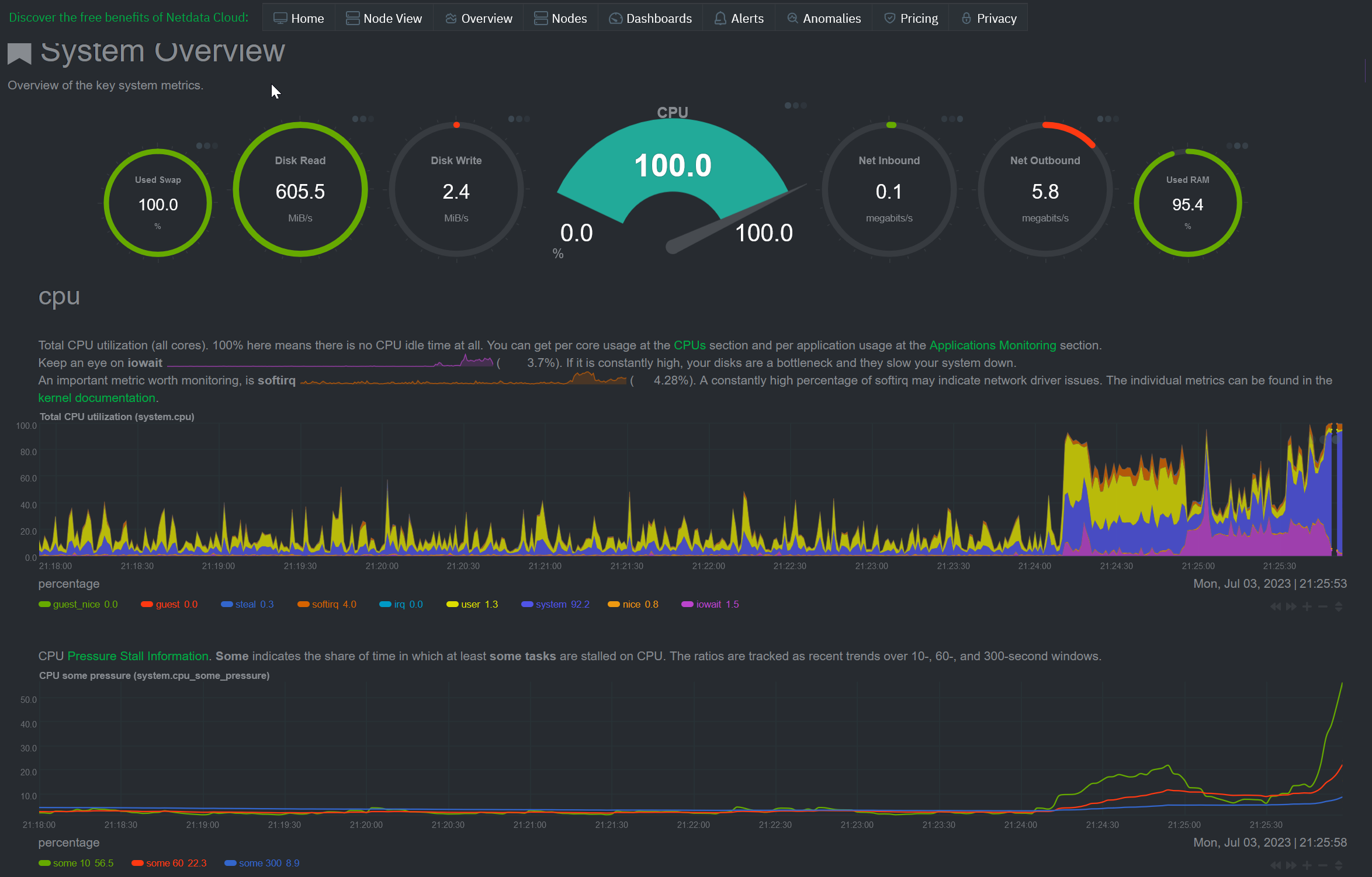
I should add that this isn't the first time this has happened, but it is the first time since I reduced the allocation of RAM for PostgreSQL in the configuration file. I swore that that was the problem, but I guess not. It's been almost a full week without any usage spikes or service interruptions of this kind, but all of a sudden, my RAM and CPU are maxing out again at regular intervals. When this occurs, the instance is unreachable until the issue resolves itself, which seemingly takes 5-10 minutes.

The usage spikes only started today out of a seven-day graph; they are far above my idle usage.
I thought the issue was something to do with Lemmy periodically fetching some sort of remote data and slamming the database, which is why I reduced the RAM allocation for PostgreSQL to 1.5 GB instead of the full 2 GB. As you can see in the above graph, my idle resource utilization is really low. Since it's probably cut off from the image, I'll add that my disk utilization is currently 25-30%. Everything seemed to be in order for basically an entire week, but this problem showed up again.
Does anyone know what is causing this? Clearly, something is happening that is loading the server more than usual.